Code understanding
![]()
Use case
Source code analysis is one of the most popular LLM applications (e.g., GitHub Copilot, Code Interpreter, Codium, and Codeium) for use-cases such as:
- Q&A over the code base to understand how it works
- Using LLMs for suggesting refactors or improvements
- Using LLMs for documenting the code
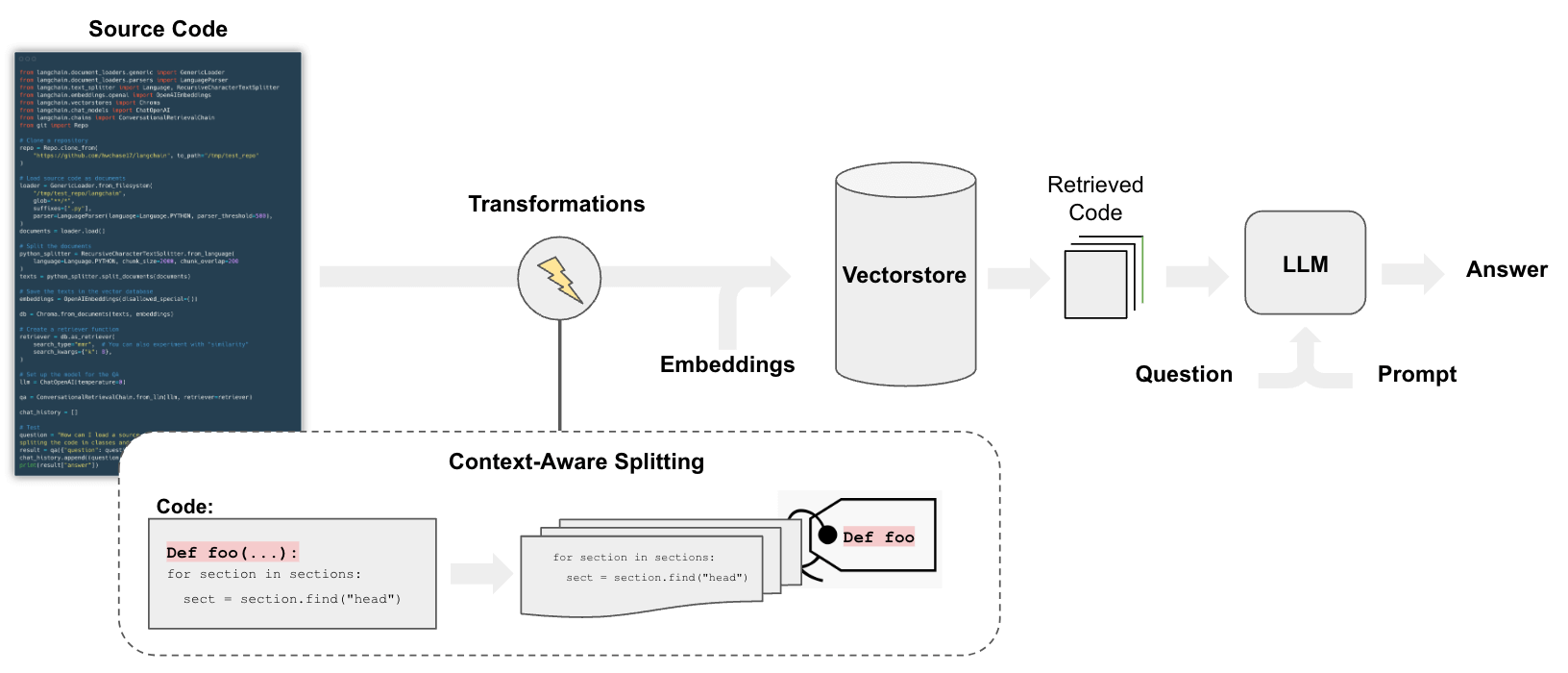
Overview
The pipeline for QA over code follows the steps we do for document question answering, with some differences:
In particular, we can employ a splitting strategy that does a few things:
- Keeps each top-level function and class in the code is loaded into separate documents.
- Puts remaining into a separate document.
- Retains metadata about where each split comes from
Quickstart
%pip install --upgrade --quiet langchain-openai tiktoken langchain-chroma langchain GitPython
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
We'll follow the structure of this notebook and employ context aware code splitting.
Loading
We will upload all python project files using the langchain_community.document_loaders.TextLoader.
The following script iterates over the files in the LangChain repository and loads every .py file (a.k.a. documents):
from git import Repo
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import LanguageParser
from langchain_text_splitters import Language
# Clone
repo_path = "/Users/jacoblee/Desktop/test_repo"
repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)
We load the py code using LanguageParser, which will:
- Keep top-level functions and classes together (into a single document)
- Put remaining code into a separate document
- Retains metadata about where each split comes from
# Load
loader = GenericLoader.from_filesystem(
repo_path + "/libs/core/langchain_core",
glob="**/*",
suffixes=[".py"],
exclude=["**/non-utf8-encoding.py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
documents = loader.load()
len(documents)
295
Splitting
Split the Document into chunks for embedding and vector storage.
We can use RecursiveCharacterTextSplitter w/ language specified.
from langchain_text_splitters import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=2000, chunk_overlap=200
)
texts = python_splitter.split_documents(documents)
len(texts)
898
RetrievalQA
We need to store the documents in a way we can semantically search for their content.
The most common approach is to embed the contents of each document then store the embedding and document in a vector store.
When setting up the vectorstore retriever:
- We test max marginal relevance for retrieval
- And 8 documents returned
Go deeper
- Browse the > 40 vectorstores integrations here.
- See further documentation on vectorstores here.
- Browse the > 30 text embedding integrations here.
- See further documentation on embedding models here.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
retriever = db.as_retriever(
search_type="mmr", # Also test "similarity"
search_kwargs={"k": 8},
)
Chat
Test chat, just as we do for chatbots.
Go deeper
- Browse the > 55 LLM and chat model integrations here.
- See further documentation on LLMs and chat models here.
- Use local LLMS: The popularity of PrivateGPT and GPT4All underscore the importance of running LLMs locally.
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages(
[
("placeholder", "{chat_history}"),
("user", "{input}"),
(
"user",
"Given the above conversation, generate a search query to look up to get information relevant to the conversation",
),
]
)
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
("placeholder", "{chat_history}"),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa = create_retrieval_chain(retriever_chain, document_chain)
question = "What is a RunnableBinding?"
result = qa.invoke({"input": question})
result["answer"]
'A RunnableBinding is a class in the LangChain library that is used to bind arguments to a Runnable. This is useful when a runnable in a chain requires an argument that is not in the output of the previous runnable or included in the user input. It returns a new Runnable with the bound arguments and configuration. The bind method in the RunnableBinding class is used to perform this operation.'
questions = [
"What classes are derived from the Runnable class?",
"What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?",
]
for question in questions:
result = qa.invoke({"input": question})
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
-> **Question**: What classes are derived from the Runnable class?
**Answer**: The classes derived from the `Runnable` class as mentioned in the context are: `RunnableLambda`, `RunnableLearnable`, `RunnableSerializable`, `RunnableWithFallbacks`.
-> **Question**: What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?
**Answer**: One potential improvement could be the introduction of abstract base classes (ABCs) or interfaces for different types of Runnable classes. Currently, it seems like there are lots of different Runnable types, like RunnableLambda, RunnableParallel, etc., each with their own methods and attributes. By defining a common interface or ABC for all these classes, we can ensure consistency and better organize the codebase. It would also make it easier to add new types of Runnable classes in the future, as they would just need to implement the methods defined in the interface or ABC.
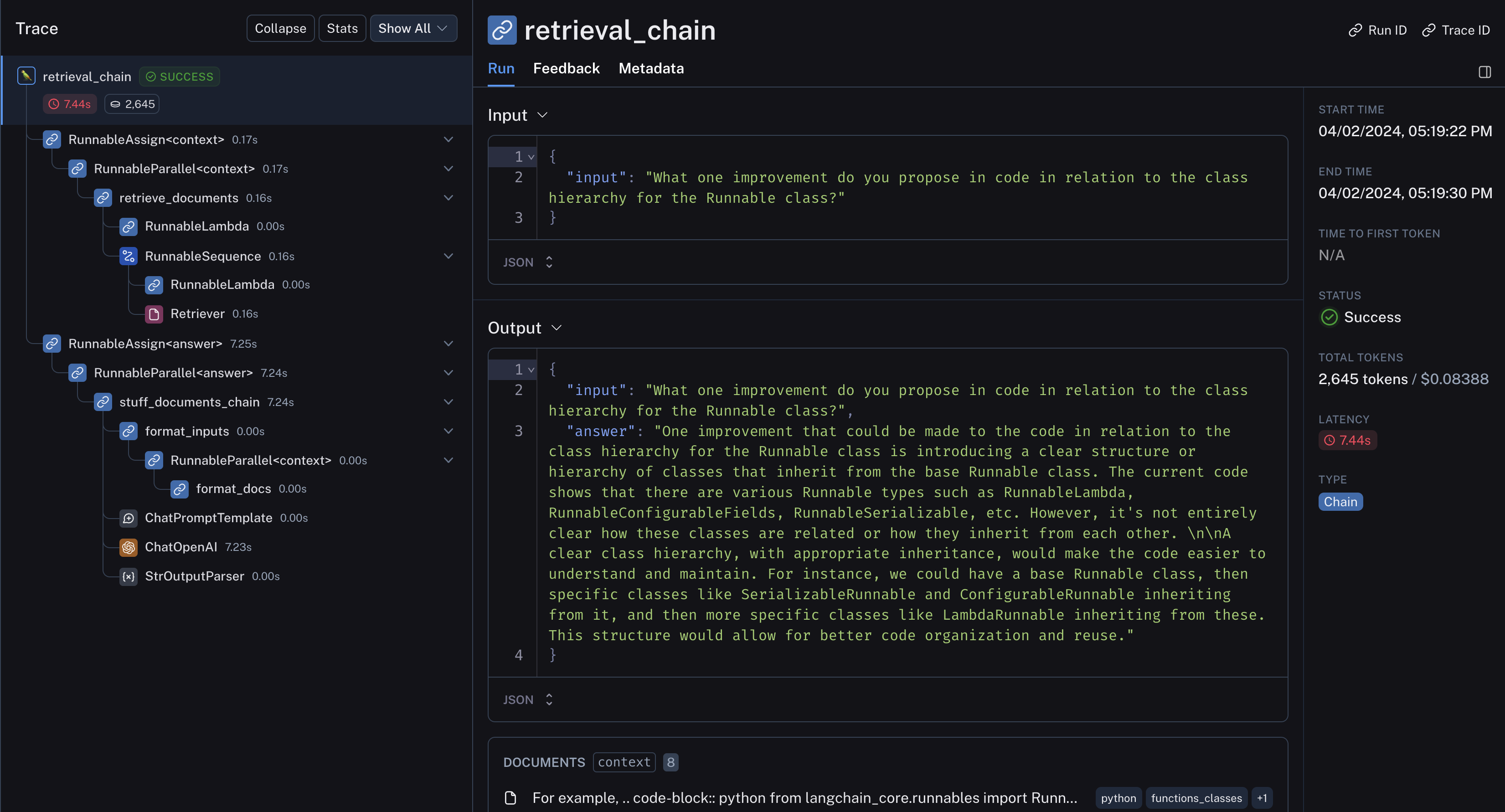
Then we can look at the LangSmith trace to see what is happening under the hood:
- In particular, the code well structured and kept together in the retrieval output
- The retrieved code and chat history are passed to the LLM for answer distillation
Open source LLMs
We'll use LangChain's Ollama integration to query a local OSS model.
Check out the latest available models here.
%pip install --upgrade --quiet langchain-community
from langchain_community.chat_models.ollama import ChatOllama
llm = ChatOllama(model="codellama")
Let's run it with a generic coding question to test its knowledge:
response_message = llm.invoke(
"In bash, how do I list all the text files in the current directory that have been modified in the last month?"
)
print(response_message.content)
print(response_message.response_metadata)
You can use the `find` command with the `-mtime` option to find all the text files in the current directory that have been modified in the last month. Here's an example command:
```bash
find . -type f -name "*.txt" -mtime -30
This will list all the text files in the current directory (.) that have been modified in the last 30 days. The -type f option ensures that only regular files are matched, and not directories or other types of files. The -name "*.txt" option restricts the search to files with a .txt extension. Finally, the -mtime -30 option specifies that we want to find files that have been modified in the last 30 days.
You can also use find command with -mmin option to find all the text files in the current directory that have been modified within the last month. Here's an example command:
find . -type f -name "*.txt" -mmin -4320
This will list all the text files in the current directory (.) that have been modified within the last 30 days. The -type f option ensures that only regular files are matched, and not directories or other types of files. The -name "*.txt" option restricts the search to files with a .txt extension. Finally, the -mmin -4320 option specifies that we want to find files that have been modified within the last 4320 minutes (which is equivalent to one month).
You can also use ls command with -l option and pipe it to grep command to filter out the text files. Here's an example command:
ls -l | grep "*.txt"
This will list all the text files in the current directory (.) that have been modified within the last 30 days. The -l option of ls command lists the files in a long format, including the modification time, and the grep command filters out the files that do not match the specified pattern.
Please note that these commands are case-sensitive, so if you have any files with different extensions (e.g., .TXT), they will not be matched by these commands.
{'model': 'codellama', 'created_at': '2024-04-03T00:41:44.014203Z', 'message': {'role': 'assistant', 'content': ''}, 'done': True, 'total_duration': 27078466916, 'load_duration': 12947208, 'prompt_eval_count': 44, 'prompt_eval_duration': 11497468000, 'eval_count': 510, 'eval_duration': 15548191000}
Looks reasonable! Now let's set it up with our previously loaded vectorstore.
We omit the conversational aspect to keep things more manageable for the lower-powered local model:
```python
# from langchain.chains.question_answering import load_qa_chain
# # Prompt
# template = """Use the following pieces of context to answer the question at the end.
# If you don't know the answer, just say that you don't know, don't try to make up an answer.
# Use three sentences maximum and keep the answer as concise as possible.
# {context}
# Question: {question}
# Helpful Answer:"""
# QA_CHAIN_PROMPT = PromptTemplate(
# input_variables=["context", "question"],
# template=template,
# )
system_template = """
Answer the user's questions based on the below context.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible:
{context}
"""
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
("user", "{input}"),
]
)
document_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, document_chain)
# Run, only returning the value under the answer key for readability
qa_chain.pick("answer").invoke({"input": "What is a RunnableBinding?"})
"A RunnableBinding is a high-level class in the LangChain framework. It's an abstraction layer that sits between a program and an LLM or other data source.\n\nThe main goal of a RunnableBinding is to enable a program, which may be a chat bot or a backend service, to fetch responses from an LLM or other data sources in a way that is easy for both the program and the data sources to use. This is achieved through a set of predefined protocols that are implemented by the RunnableBinding.\n\nThe protocols defined by a RunnableBinding include:\n\n1. Fetching inputs from the program. The RunnableBinding should be able to receive inputs from the program and translate them into a format that can be processed by the LLM or other data sources.\n2. Translating outputs from the LLM or other data sources into something that can be returned to the program. This includes converting the raw output of an LLM into something that is easier for the program to process, such as text or a structured object.\n3. Handling errors that may arise during the fetching, processing, and returning of responses from the LLM or other data sources. The RunnableBinding should be able to catch exceptions and errors that occur during these operations and return a suitable error message or response to the program.\n4. Managing concurrency and parallelism in the communication with the LLM or other data sources. This may include things like allowing multiple requests to be sent to the LLM or other data sources simultaneously, handling the responses asynchronously, and retrying failed requests.\n5. Providing a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources. This could include things like setting up credentials, providing additional contextual information to the LLM or other data sources, and controlling logging or error handling behavior.\n\nIn summary, a RunnableBinding provides a way for a program to easily communicate with an LLM or other data sources without having to know about the details of how they work. By providing a consistent interface between the program and the data sources, the RunnableBinding enables more robust and scalable communication protocols that are easier for both parties to use.\n\nIn the context of the chatbot tutorial, a RunnableBinding may be used to fetch responses from an LLM and return them as output for the bot to process. The RunnableBinding could also be used to handle errors that occur during this process, such as providing error messages or retrying failed requests to the LLM.\n\nTo summarize:\n\n* A RunnableBinding provides a way for a program to communicate with an LLM or other data sources without having to know about the details of how they work.\n* It enables more robust and scalable communication protocols that are easier for both parties to use.\n* It manages concurrency and parallelism in the communication with the LLM or other data sources.\n* It provides a way for the program to set configuration options that affect how the RunnableBinding interacts with the LLM or other data sources."
Not perfect, but it did pick up on the fact that it lets the developer set configuration option!
Here's the LangSmith trace showing the retrieved docs used as context.